# Setting Up Ollama (Local Provider)
vREST also supports using local Large Language Models (LLMs) via Ollama (opens new window), allowing you to run models directly on your machine without using any cloud API keys.
This is ideal for:
- Users who want to keep data local
- Those who prefer not to rely on third-party hosted services
- Developers experimenting with custom or open-source models
# Step-by-Step Guide
# Step 1: Install Ollama
Go to the Ollama official site (opens new window) and download the appropriate version for your OS (Windows, macOS, Linux).
Once installed, open a terminal and run:
ollama --version
You should see a version number if it's installed correctly.
# Step 2: Download and Run a Model
Let’s use llama2 as an example model.
ollama pull llama2
ollama run llama2
ollama pull llama2→ Downloads the LLaMA2 model to your machine.ollama run llama2→ Starts serving the model on a local endpoint (http://localhost:11434by default).
You can replace
llama2with other models supported by Ollama likemistral,phi, orcodellama.
# Step 3: Configure in vREST
- Open vREST NG.
- Navigate to the AI Settings tab.
- Enter the following endpoint in the Local Provider section:
http://localhost:11434
- Click Verify.
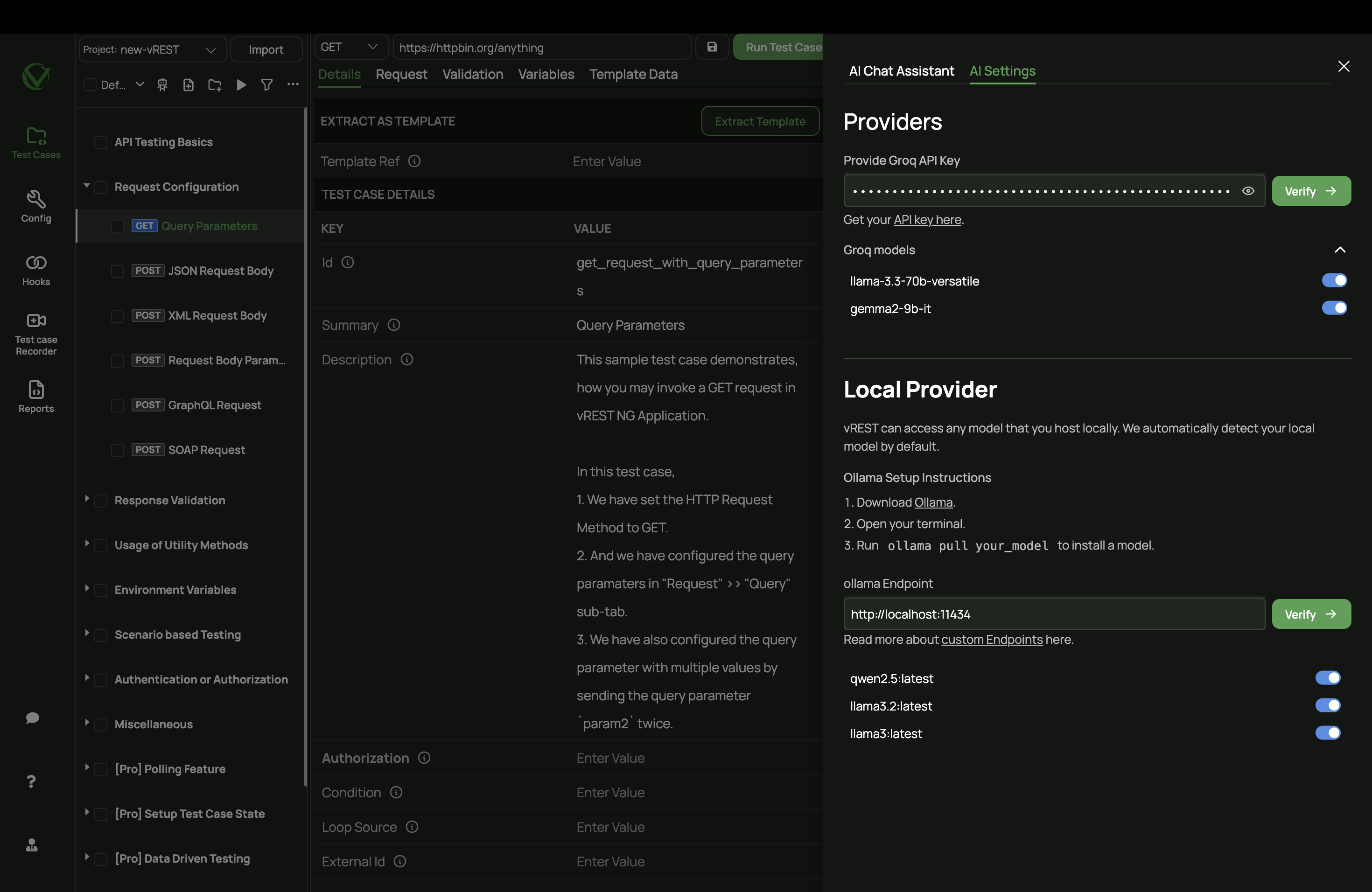
If everything is set up correctly:
- You’ll see a success message.
- All models running locally will be automatically detected and enabled.
# Not Familiar with Ollama?
Ollama is a lightweight, open-source tool that allows you to run powerful AI models locally on your machine with minimal setup. It takes care of serving the model through a simple HTTP API, so you can integrate it with vREST easily.
No need to write code, just pull, run, and connect.